
The SQL Profiler is a great tool for monitoring and analyzing SQL Server Performance. I use it all the time to watch the detailed actions of a stored procedure, trigger or user-defined function (UDF) that I am developing. It can also be used to monitor aggregate performance of an entire SQL Server instance, a single database, or to isolate performance problems. When you are interested in overall performance, using SQL Profiler over time, by that I mean every day, improves your knowledge of your system and its performance characteristics and provides the information you need to spot trends and changes of behavior.
SQL Profiler is a graphical interface to SQL Server’s trace capability but it is not the only way to run a trace. Calling a group of system stored procedures, whose names all begin with the characters “sp_trace_”, can also create them. In fact, SQL Profiler uses these stored procedures behind the scenes to do the tracing that you request.
Traces can be sent to the SQL Profiler window, a database table or a sequential disk file. However, tracing is not resource free. In fact, it can consume considerable resources, particularly if you send the trace to SQL Profiler. Since the most important time to monitor is the time of maximum server load, you do not want the act of measurement to slow the system unnecessarily. For most applications that run in a business environment, peak activity occurs in the middle of the afternoon.
The disk file is by far and away the fastest destination for a trace and it interferes the least with the performance of SQL Server. However, for analysis purposes, a table is the best destination. Once the data is in a table, the information can be sliced and diced to your heart’s content. Most importantly, trend reporting, using data from multiple days, is possible.
This article presents a technique for writing a stored procedure that creates a trace. To achieve the best performance the procedure sends its output to a file on disk. A second step moves the data from the trace file into a SQL table for analysis. The second step doesn’t have to be performed exactly when the data is recorded. In fact, it’s usually loaded overnight when server utilization is low and then followed by any standard reports. By using the file as the trace destination and loading the data overnight, this solution does the best to minimize the peak-hour resources required for monitoring.
Although you could manually use the SQL Profiler to create a trace at the same time every day and send it to a file, it is difficult to be consistent and this is a task that is easily automated. By using the stored procedure and a SQL Job that runs the stored procedure, you can run the exact same trace at the same time of day, every day. This kind of data gathering provides consistent information for effective performance analysis.
The most tedious part of the process is creating the stored procedure that executes the trace. Fortunately, SQL Profiler will write almost all of it for you. With a few modifications, it is easy to turn its script into a stored procedure that can be run on a schedule.
Creating the Trace Script
To create the trace, fire up SQL Profiler and use it to define the trace. You do not have to do anything special to create the trace but completing a few fields in the GUI makes life easier. Normally, when you use the Trace Properties Form to ask that the trace sent to a file and not to SQL Profiler’s screen, you select a “server trace.” Do that and fill in a file name when it asks. You should use the fields at the bottom of the General tab to “Enable trace stop time” and fill in a time. Do not worry what time to stop at; it will be changed when the stored procedure is created.
Figure 1 shows the General tab as I used SQL Profiler to create the trace. I started with the SQLStandard.trc trace template and specified “Save to file” and a trace stop time.
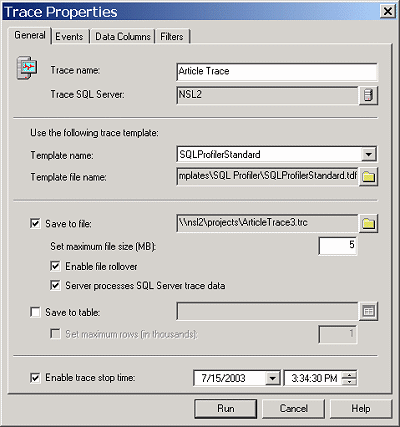
The contents of the other tabs are not critical to understanding the scripting technique because when SQL Profiler creates the script, it is going to add the events, data columns and filters that you ask for. In this case, among other things, I am looking for table scans, lock deadlocks and statements that take over 100 milliseconds to execute.
There is a little bit of a trick to setting up the filter: all conditions are combined with the AND operator. That is, the trace only records an event when all the expressions in the filter are satisfied. To make sure that the script does not filter out too much, I have used a 100-millisecond filter on duration, not CPU time because deadlocks do not consume CPU, they just make a query run until the deadlock timeout.
Once you are satisfied with the definition of the trace, run it, stop it and then use SQL Profiler’s menu command File -> Export-> Script Trace Definition-> For SQL Server 2005 – 2008 R2. When asked, give it a file name to save the script. The following listing shows the first few lines of the output:
/* Created by: SQL Profiler */
/* Date: 07/14/2003 04:29:56 PM */
/****************************************************/— Create a Queue
declare @rc int
declare @TraceID int
declare @maxfilesize bigint
declare @DateTime datetimeset @DateTime = ‘2003-07-14 18:29:20.000’
set @maxfilesize = 5
exec @rc = sp_trace_create @TraceID output, 2
, N’\\NSL2\Projects\Article2.trc’, @maxfilesize, @Datetime
if (@rc != 0) goto error— Client side File and Table cannot be scripted— Set the events
declare @on bit
set @on = 1
exec sp_trace_setevent @TraceID, 10, 1, @on
exec sp_trace_setevent @TraceID, 10, 12, @on
exec sp_trace_setevent @TraceID, 10, 13, @on
SQL Profiler creates a script that duplicates the trace that you specified using the GUI screens.
The script to add all the events and columns to the trace runs on for several pages and there is no need to look at more than the first few lines. However, it’s a script, or batch, not a stored procedure. There is some work to turn it into a more usable form. That’s the next task. These are the requirements:
- Turn the script into a stored procedure that can be run at any time.
- The proc should take the duration to run the trace.
- Create an output file name that is sure to be unique.
- Set the trace end time based on the current time and the duration that is requested.
All three parts are pretty easy. I name the stored procedure dba_Trc_Northwind1 to distinguish it from any other traces that I might be running. Creating a unique file name based on the time is not particularly difficult either. To insure uniqueness put the date and time into the filename in a form that is both a valid file name, one without colons or slashes, and one that sorts based on the date and time. I have used a UDF, udf_DT_FilenameFmt, from my library to form the name. You can get the UDF from a Volume 1 Issue 36 of my T-SQL UDF of the
Week newsletter.
After adding the stored procedure header and the code to calculate the end time, the top of the trace looks like the listing that follows. The shaded area calculates the file name and trace stop time before calling sp_trace_create to begin the process that defines the trace.
, @TraceID int OUTPUT — Return the TraceID to the caller.
WITH RECOMPILE
/*
* Creates a trace on the Northwind database.
***********************************************************************/
AS
declare @rc int
declare @dbaTraceID int
declare @maxfilesize bigint
declare @DateTime datetime
DECLARE @FileName nvarchar(256)
, @StartDT datetime — When the trace startedSELECT @StartDT = getdate()
+ dbo.udf_DT_FileNameFmt (getdate(), 1, 1)
, @DateTime = DATEADD (s, @Sec, @StartDT)
set @maxfilesize = 5
exec @rc = sp_trace_create @TraceID output, 2, @FileName, @maxfilesize, @Datetime
if (@rc != 0) goto error
— Set the events
declare @on bit = 1
exec sp_trace_setevent @TraceID, 10, 1, @on
exec sp_trace_setevent @TraceID, 10, 12, @on
Later in the day, when activity has died down, the trace file will be loaded into a table for analysis. To facilitate that process and for keeping track of the traces, the file name, start time, person responsible, and a comment for each trace is recorded in the tabledbaTrace. Here is the script to create it:
dbaTraceID int IDENTITY (1, 1) NOT NULL ,
TraceID int NOT NULL ,
StartDT datetime NOT NULL ,
EndDT datetime NOT NULL ,
[FileName] nvarchar (255) NULL ,
FileLoadedDT datetime NULL ,
Responsible nvarchar (128) NULL ,
Description nvarchar (255) NULL
, CONSTRAINT dbaTrace_PK PRIMARY KEY CLUSTERED (dbaTraceID)
) ON [PRIMARY]
GO
The bottom portion of the stored procedure takes care of inserting a row in the dbaTrace table by calling the stored procedure dba_Trc_Record. Here is the last dozen or so lines of dba_Trc_Northwind1:
exec sp_trace_setstatus @TraceID, 1
— display trace id for future references
— select TraceID=@TraceID
EXEC @RC = dba_Trc_Record @Filename, @StartDT, @Sec, ‘Andy’
, ‘Scripted Trace for Northwind scans and deadlocks’
, @TraceID, @dbaTraceID OUTPUT
PRINT ‘dbaTrace.dbaTraceID = ‘ + CONVERT(varchar(9), @dbaTraceID)
goto finish
error:
SELECT ErrorCode=@rc
finish:
And here is dba_Trc_Record:
@FileName nvarchar(256) — File to load
, @StartDT datetime
, @Sec int = 600 — Seconds of duration
, @Resp nvarchar(255) — Who is responsible
, @Desc nvarchar(2000)– Description
, @SQLtraceID int — SQL Server’s ID of the Trace
, @dbaTraceID int OUTPUT — Id of dbaTrace use
AS
/*
* Creates a row in dbaTrace row to record a trace file. The
* trace file can be loaded later.
*
* Example:
DECLARE @TraceID int, @RC int, @StartDT datetime
SET @StartDT = GETDATE()
EXEC @RC = dbo.dba_Trc_Record ‘c:\ExampleTrace.trc’, @StartDT
, 600, ‘Andy’, ‘Example Trace’, 1, @TraceID OUTPUT
PRINT ‘RC = ‘+ CONVERT (varchar(9), @RC)
+ ‘ New ID =’ + CONVERT(varchar(9), @TraceID)
****************************************************************/
DECLARE @myError int — Local copy of @@Error
, @myRowcount int — Local copy of @@ROWCOUNT
SET NOCOUNT ON — Don’t report the count of effected rows
INSERT INTO dbaTrace (TraceID, StartDT, EndDT, [FileName]
, Responsible, [Description])
VALUES (@SQLtraceID, @StartDT
, DATEADD (s, @Sec, @StartDT)
, @FileName, @Resp, @Desc)
SELECT @myError = @@Error, @myRowcount = @@Rowcount
IF @myError <> 0 or @myRowCount <> 1 BEGIN
RETURN @myError
END
SELECT @dbaTraceID = SCOPE_IDENTITY()
RETURN 0
GO
Since this stored procedure is going to be invoked by a SQL Job, PRINT statements are the way to get information into the log of the Job step that invokes it. That is why I commented out the “select TraceID=@TraceID” statement. Instead, the two PRINT statements in the shaded area show SQL Server’s ID for the trace and dbaTraceID, which is the key to the dbaTrace table.
The job is real simple. Just one step that invokes dba_Trc_Northwind1 and supplies the number of seconds for the trace: Here’s the text of the only step:
EXEC @rc = dba_Trc_Northwind1 600, @dbaTraceID OUTPUT
PRINT ‘RC from starting Trace = ‘ + convert(varchar(9), @rc)
PRINT ‘DBA TraceID = ‘ + convert(varchar(9), @dbaTraceID)
I have used 600 seconds for 10 minutes of monitoring. During a period of heavy activity, that seems to be sufficient.
Loading the Trace Script into a Table
Working with trace data in disk file is not easy. I suppose it is possible to load the data into Excel, STATA, MatLab, R, SAS, or some other analysis tool. However, I find that the best place to work with the data is in a SQL table. The next step in the process loads the trace file on disk into a table for analysis.
If you ask SQL Profiler to create the trace into a table for you, it creates a table with just the columns that you have selected for the trace. Since SQL Profiler knows which columns it’s recording, letting it create a table is sufficient for one time use. However, for reporting purposes, having different traces in different tables is inconvenient. The best approach is to use a table that can store all columns of any trace. Having a single table also helps because there might be additional columns recorded as the trace is modified over time. The next listing has the CREATE TABLE script for dbaTraceDetailthat does just that.
dbaTraceID int NOT NULL ,
RowNumber int IDENTITY (1, 1) NOT NULL ,
StartTime datetime NULL ,
EndTime datetime NULL ,
EventClass int NULL ,
EventSubClass int NULL ,
TextData ntext NULL ,
BinaryData image NULL ,
Duration bigint NULL ,
Reads bigint NULL ,
Writes bigint NULL ,
CPU int NULL ,
DatabaseID int NULL ,
DatabaseName nvarchar (128) NULL ,
TransactionID bigint NULL ,
SPID int NULL ,
NTUserName nvarchar (128) NULL ,
NTDomainName nvarchar (128) NULL ,
HostName nvarchar (128) NULL ,
ClientProcessID int NULL ,
LoginName nvarchar (128) NULL ,
DBUserName nvarchar (128) NULL ,
ApplicationName nvarchar (128) NULL ,
[Permissions] int NULL ,
Severity int NULL ,
Success int NULL ,
IndexID int NULL ,
IntegerData int NULL ,
ServerName nvarchar (128) NULL ,
ObjectType int NULL ,
NestLevel int NULL ,
State int NULL ,
Error int NULL ,
Mode int NULL ,
Handle int NULL ,
ObjectID int NULL ,
ObjectName nvarchar (128) NULL ,
FileName nvarchar (128) NULL ,
OwnerName nvarchar (128) NULL ,
RoleName nvarchar (128) NULL ,
TargetUserName nvarchar (128) NULL ,
LoginSid image NULL ,
TargetLoginName nvarchar (128) NULL ,
TargetLoginSid image NULL ,
ColumnPermissions int NULL
, CONSTRAINT dbaTraceDetail_PK PRIMARY KEY CLUSTERED (dbaTraceID, RowNumber ) on [PRIMARY]
REFERENCES dbo.dbaTrace (dbaTraceID)
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
As you can see near the bottom of the script, the table has a foreign key relationship with the dbaTrace table created in the previous section. By having the dbaTraceID column the lead part of the key, many traces can be kept in the same table. Since the table has every column that could be included in a trace, any trace can be loaded into it.
Loading the table from the trace file relies on one of SQL Server’s system user-defined functions. “System” and “user-defined” might sound like a contradiction, but they are functions, written in T-SQL using the CREATE FUNCTION statement, that SQL Server adds to itself during installation. The function in question is fn_trace_gettable. It is incorporated into the stored procedure dba_Trc_LoadFile that follows.
CREATE PROCEDURE dbo.dba_Trc_LoadFile
@FileName nvarchar(256) — File to load
, @dbaTraceID int — Id of dbaTrace use
, @DeleteOldRows BIT = 1 — Should Old Rows be removed?
, @RowsLoaded int OUTPUT — Rows of trace data loaded
AS
/*
* Loads a trace file from disk into the dbaTraceDetail table and
* updates the corresponding dbaTrace row to reflect that the file
* has bee loaded.
*
DECLARE @Rows int, @RC int
exec @RC = dbo.dba_Trc_LoadFile ‘c:\ExampleTrace.trc’
, 1 , default, @Rows OUTPUT
PRINT ‘Loaded ‘ + CONVERT(varchar(9), @Rows) + ‘ Rows RC = ‘
+ CONVERT (varchar(9), @RC)
****************************************************************/
DECLARE @myError int — Local copy of @@Error
, @myRowcount int — Local copy of @@ROWCOUNT
SET NOCOUNT ON — Don’t report the count of effected rows
BEGIN TRANSACTION
— Remove any old rows from the trace.
IF @DeleteOldRows = 1 BEGIN
DELETE FROM dbo.dbaTraceDetail WHERE dbaTraceID=@dbaTraceID
SELECT @myError = @@Error, @myRowcount = @@Rowcount
IF @myError <> 0 BEGIN
ROLLBACK TRANSACTION
RETURN @myError
END
END
— This statement loads the file
INSERT INTO dbo.dbaTraceDetail
(dbaTraceID, StartTime, EndTime, EventClass, EventSubClass
, TextData, BinaryData, Duration, Reads, Writes, CPU, DatabaseID
, DatabaseName, TransactionID, SPID, NTUserName, NTDomainName
, HostName, ClientProcessID, LoginName, DBUserName
, ApplicationName, [Permissions], Severity, Success, IndexID
, IntegerData, ServerName, ObjectType, NestLevel, State, Error
, Mode, Handle, ObjectID, ObjectName, [FileName], OwnerName
, RoleName, TargetUserName, LoginSid
, TargetLoginName, TargetLoginSid, ColumnPermissions)
SELECT @dbaTraceID, StartTime, EndTime, EventClass, EventSubClass
, TextData, BinaryData, Duration, Reads, Writes, CPU, DatabaseID
, DatabaseName, TransactionID, SPID, NTUserName, NTDomainName
, HostName, ClientProcessID, LoginName, DBUserName
, ApplicationName, [Permissions], Severity, Success, IndexID
, IntegerData, ServerName, ObjectType, NestLevel, State, Error
, Mode, Handle, ObjectID, ObjectName, [FileName], OwnerName
, RoleName, TargetUserName, LoginSid
, TargetLoginName, TargetLoginSid, ColumnPermissions
FROM ::fn_trace_gettable(@FileName, default)
SELECT @myError = @@Error, @myRowcount = @@Rowcount
IF @myError <> 0 BEGIN
ROLLBACK TRANSACTION
RETURN @myError
END
SET @RowsLoaded = @myRowcount — Save the count for output
— Update the time when the file was loaded.
UPDATE dbo.dbaTrace
SET FileLoadedDT = getdate()
WHERE @dbaTraceID = dbaTraceID
SELECT @myError = @@Error, @myRowcount = @@Rowcount
IF @myError <> 0 BEGIN
ROLLBACK TRANSACTION
RETURN @myError
END
COMMIT TRANSACTION
SELECT @myError = @@Error
RETURN @myError — Should be zero, unless there was an error on COMMIT
Unless I am really interested in seeing what’s in the trace, I run this in a separate job that loads all the available files. It is scheduled to run in the early morning hours when system activity is low.
Conclusion
By using SQL Profiler’s ability to create the T-SQL script for a trace, this article has shown how easy it is to create a stored procedure that can be run every day during times of peak activity. That is the best time to find out where SQL Server is using the most resources so any performance problems can be addressed. By shifting the effort of loading the data to an off peak time, the overhead of monitoring performance is moved out of peak hours.
Of course, what you have seen here is the process of gathering the performance data. Once you have it, there are various ways to analyze it. I usually run a variety of reports that show the longest running statements, the table scans, or any deadlocks that have occurred.