User-Defined functions (UDF) have been around SQL Server since the 2000 version. They are a great way to encapsulate business logic in a reusable form. There are there types of UDFs:
Scalar Functions – Returns a single scalar value (int, real, varchar, etc.)
Table Valued Functions – Returns a @Table of one or more columns
Inline Functions – Returns the results of a SELECT statement. (A view with parameters)
However, from the start scalar and Table-Valued functions have suffered from a performance problem when they’re used in a query that touches a large number of rows. This article and the accompanying video on you-tube demonstrate the problem and the solution. There are two problems when using scalar and table-valued UDFs:
use of the function causes Row-by-Agonizing-Row (RBAR) processing like a cursor
Use of the function Inhibits Parallelism in the query
For an example function I’ll use the exponential-moving-average function (EMA). It’s used in many scientific and analytic fields including investment management were I’m working now. It gives an average over a time period but it’s advantage is that it can be updated on each new period by referring only to the previous period’s EMA and the new value.
Exponential Moving Average formula
This can be expressed as a scalar T-SQL User-Defined Function like this:
CREATEFUNCTION[dbo].[exp_moving_avg_scalar](
@ema_yesterdayFLOAT ,@value_todayFLOAT ,@daysINT,@smoothingFLOAT=2.0 ) RETURNSFLOAT/* Single value exponential moving average (EMA)** Example:select dbo.exp_moving_avg_scalar(3.545, 2.123, 21, default)** When* 2013-10-11 Andy Novick Initial Coding***********************************************************************/
AS BEGINRETURNCASEWHEN@ema_yesterdayISNULL THEN@value_today ELSE@value_today*(@smoothing/(1.0+@days)))+( @ema_yesterday*(1.0–(@smoothing/(1.0+@days)))END
END
There is a straight forward but non-obvious solution to the performance problem that involves replacing the scalar or table-valued function with an inline function. Here’s the equivalent inline UDF:
CREATEFUNCTION[dbo].[exp_moving_avg_inline](@ema_yesterdayFLOAT ,@value_todayFLOAT ,@daysINT ,@smoothingFLOAT=2.0 ) returnsTABLE /* Single value exponential moving average (EMA)* * Example: select ema_today from dbo.exp_moving_avg_inline(3.545, 2.123, 21, default) * * When * 2013-10-11 Andy Novick Initial Coding ***********************************************************************/AS RETURN SELECTCASE WHEN@ema_yesterdayISNULLTHEN@value_today ELSE@value_today*(@smoothing/(1.0+@days)))+( @ema_yesterday*(1.0–(@smoothing/(1.0+@days))) ENDASema_today
And there’s an important difference in the way that a inline UDF is called vs a scalar UDF. Calling a scalar UDF is pretty simple and very much like other programming languages. The UDF goes into the SQL any place that you could use an expression. Here’s an example with the function on the third line:
Unfortunately a inline UDF doesn’t just drop into place where the scalar UDF once was. Instead it has to be in a sub-query, which makes the change more difficult. Here’s what the above SELECT it looks like with the lnline UDF:
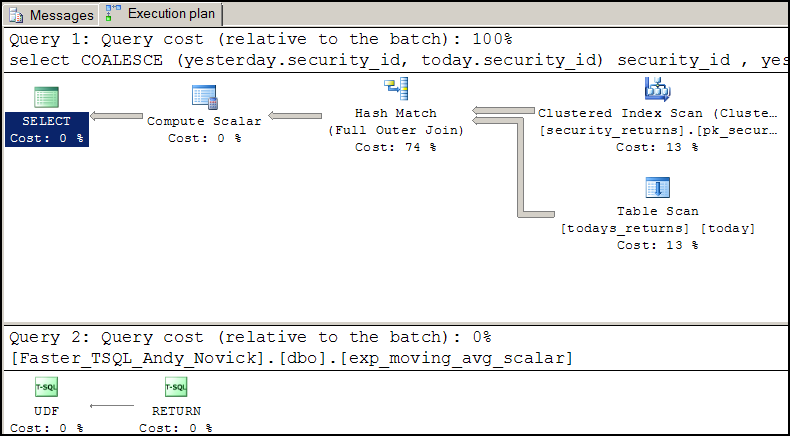
The proof is in the query plan. Instead of having a non-parallel plan with the scalar UDF like this:
query plan for using exponential weighted scalar UDF in a SELECT Statement.
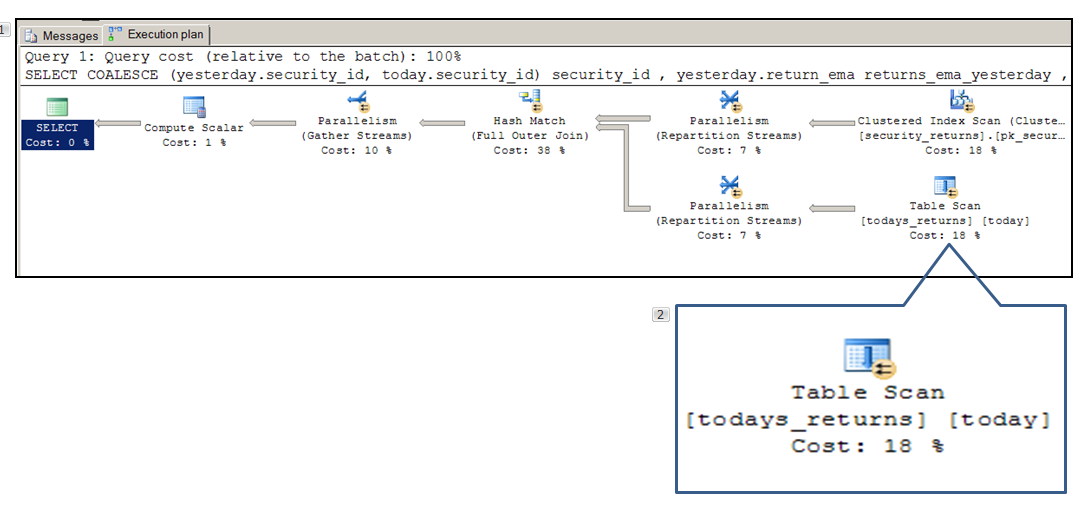
Now take a look at the plan that uses the Inline UDF:
Query plan when the lnline UDF has been used to replace the scalar UDF. Now it’s parallel
Notice the small orange circiles with the double arrows pointing left. These symbols indicate that the query plan node is a parallel node. It will use as many processors as are available instead of just one like the query with the scalar UDF. On my system with 4 cores I find the results when using an inline UDF are 2 to 4 times faster than when using the scalar UDF. The performance difference can also
“Software performance was our single biggest problem. We did everything we could do in-house to get the database running like it should and really needed some help. You quickly pinpointed problem areas and your setup, index and query recommendations greatly improved the software’s performance.”
Daniel J. Mc Intyre, Vice President
Management Computer Services, Inc.